

 Leichte Sprache
Leichte SpracheVon der Edge zur Cloud und zurück: Skalierbare und Adaptive Sensordatenverarbeitung
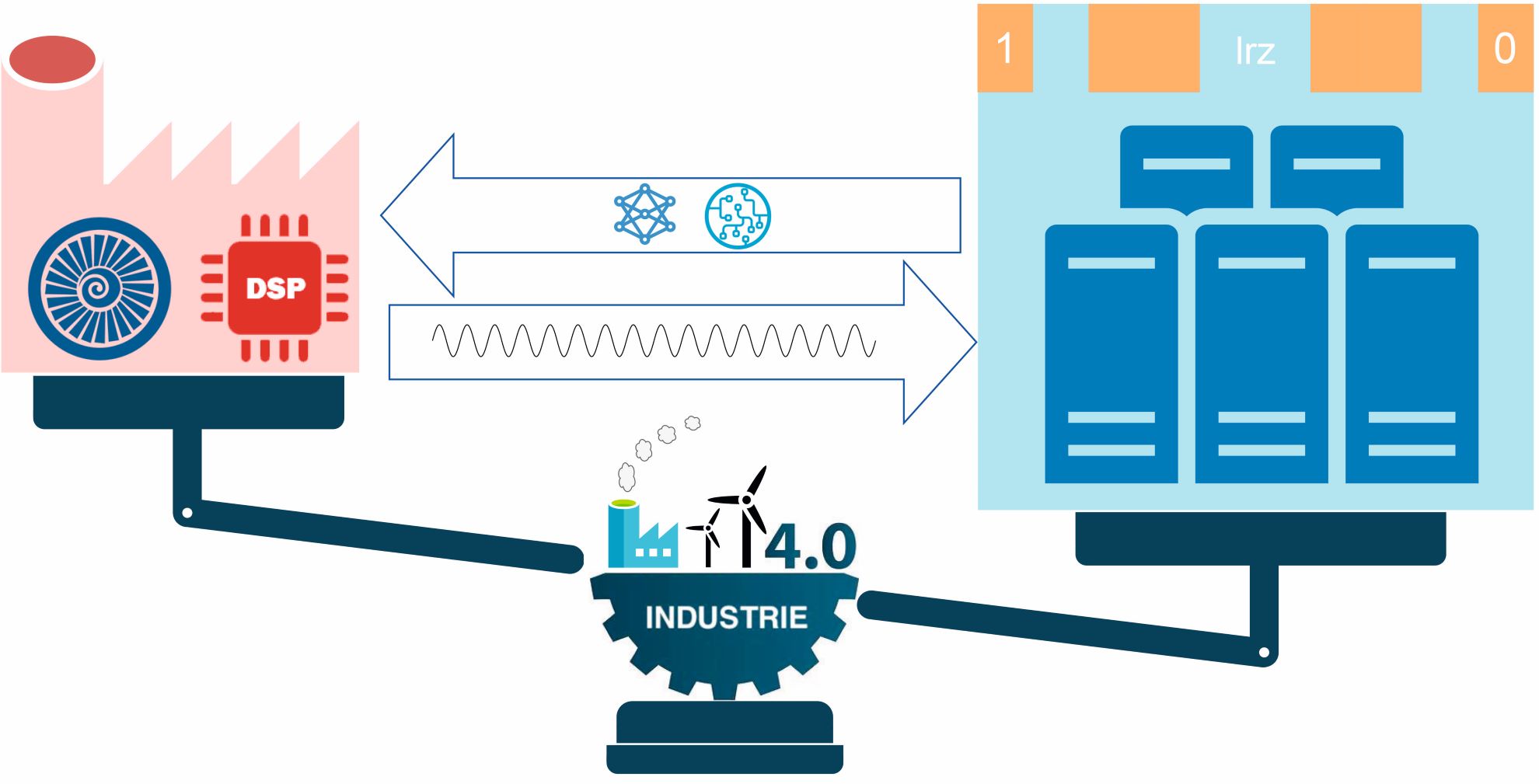
Daten werden von Sensoren generiert und vor Ort vorverarbeitet (links). In einem zentralen Rechensystem (rechts) steht mehr Rechenkapazität zur Verfügung, um komplexere Analysen auszuführen. Ergebnisse können dann zurückübertragen und für präzisere Analysen an der Edge eingesetzt werden (Quelle: IfTA GmbH, TU München)
Die uneingeschränkte Verfügbarkeit systemkritischer Infrastruktur ist essenziell für eine funktionierende Gesellschaft. Anlagen zur Energie- und Trinkwasserversorgung, Mobilitäts- und Kommunikationsinfrastruktur und viele weitere Systeme werden daher dauerhaft mit Sensoren überwacht. Die dabei anfallenden Datenmengen sind enorm. Für ihre Analyse bedarf es einer intelligenten Nutzung der verfügbaren Rechenressourcen sowohl vor Ort – nahe den Sensoren (an der „Edge“) – als auch in Hochleistungsrechnern oder in der Cloud.
Ziel des Forschungsprojekts ist eine effiziente Kombination aller verfügbaren Ressourcen für eine umfassende Sensordatenverarbeitung von der Edge bis in die Cloud. Dabei wird vor allem auf Skalierbarkeit und Adaptivität Wert gelegt. Gleichzeitig soll eine intelligente Kopplung aller Systemkomponenten und Daten gewährleistet werden.
In diesem Projekt wird diese Vision umgesetzt: Kleine und energiesparende Systeme vor Ort analysieren lokal verfügbare Sensordaten und steuern damit lokale Regelkreise. Gleichzeitig werden die lokal erzeugten Analyseergebnisse sowie eine ausgewählte Teilmenge der Sensordaten in die Cloud beziehungsweise an Hochleistungsrechner weitergeleitet, um Analyseverfahren zu verfeinern und Daten von mehreren Anlagen zu kombinieren. Hierdurch können verbesserte Analyseverfahren außerhalb der Edge entwickelt werden, welche dann zu den Systemen an der Edge zurückpropagiert werden, um lokale Regelkreise zu optimieren.
